Threat modelling For AI model: Customer Support Chatbot
In this lab, you will build a high-level (L1) threat model for a LLM application, identifying vulnerabilities and proposing mitigations. This lab consists of four parts, as follows:
- Building a Data Flow Diagram (DFD)
- Defining Trust Boundaries
- Using STRIDE to examine the system and define Pros/Cons
- Developing a Mitigation Strategy
Tools
- You will need access to software that allows you to draw diagrams, such as
Draw.ioor similar tools.- Use this, Draw.io, it's free.
Keep in mind that there are no right or wrong answers here; it's about considering all possible scenarios. Different people may interpret the system in various ways, so aim to cover a broad range of possibilities
Part-1: Define/Draw DFD
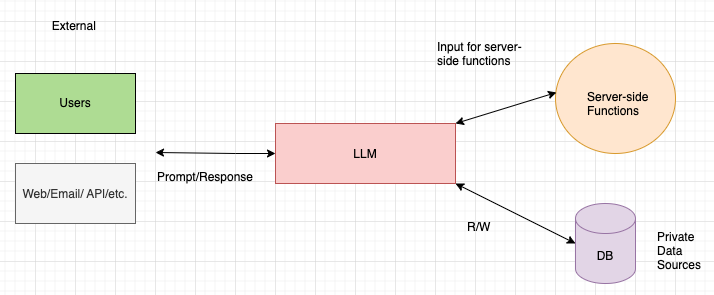
Senario: A company deploys an AI-based chatbot to assist customers with common support queries on their website. The chatbot interprets user questions and provides helpful responses, sometimes drawing on internal company data to personalise or enhance answers.
System Components
Step 1: Identifying Components
-
External Prompt Sources:
- Question: What kinds of inputs might come from outside the system? Think about how users might interact with the chatbot.
- Hint: Consider the website, email bodies, and social media content. What kind of information would a user provide for support?
-
LLM Model:
- Question: How would the chatbot use an LLM to understand and respond to a query? What is the main function of this component?
- Hint: Think about the role of the LLM in interpreting the user's input and generating a response.
-
Server-Side Functions:
- Question: If the chatbot needs to perform actions beyond simply generating responses, what additional functions would it need? What server-side processes might help manage or filter responses?
- Hint: Consider functions that could check responses for sensitive information, modify response formats, or handle complex backend interactions.
-
Private Data Sources:
- Question: What kind of private data might enhance responses? When might the chatbot need to reference this data?
- Hint: Think about internal documentation, past customer interactions, or product information. When would this information be helpful to personalise a response?
Task-1: Mapping Data Flow
Now that you have the main components, let’s map the data flow step-by-step. Think about how data moves from the user to the final response. The follwing might help:
-
User Input:
- Question: When a user submits a query on the website, what component should handle it first?
- Hint: Consider where the input enters the system and how it reaches the LLM for processing.
-
Processing by the LLM:
- Question: After receiving the user’s input, what does the LLM do with it?
- Hint: The LLM interprets the query. What might it need to do next to refine or enhance its response?
-
Interaction with Server-Side Functions:
- Question: Are there any checks or functions needed before the response is finalised? How would server-side functions interact with the LLM or the response?
- Hint: Think about filtering content or ensuring responses meet certain criteria. How might server-side functions refine or structure the response?
-
Accessing Private Data Sources:
- Question: If the chatbot needs specific information to answer the user, what component would retrieve this data? How is this data controlled?
- Hint: Only some responses require private data. What permissions or controls might be needed?
-
Response to the User:
- Question: After processing the response, how does the final answer reach the user? What last steps are taken to ensure the response is safe and accurate?
- Hint: Consider any final checks before the response is sent back through the website interface.
Task-1: Answer
Click to view a possible answer
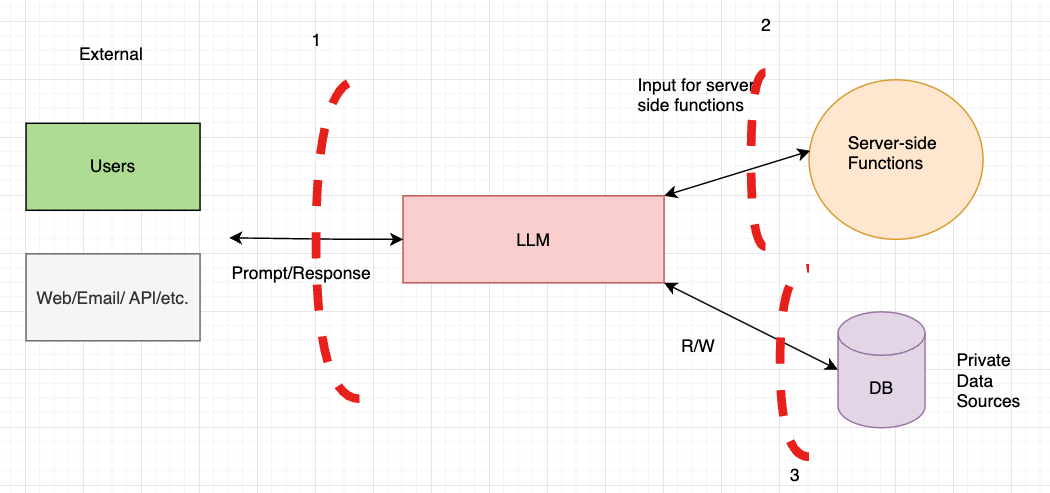
Step 2: Identifying Trust Boundaries (TB)
Once you have mapped out the data flow, consider where the potential trust boundaries should be.
Task-2: Define TBs
-
Question: Where does the user input cross into the system and interact with the LLM?
- Hint: This is where untrusted external input meets the system, a potential source of injection attacks or manipulative prompts.
-
Question: Where does the LLM interact with the server-side functions? What could go wrong if the output isn’t verified?
- Hint: Think about filtering or validating LLM output before it’s used by backend systems.
-
Question: Where is the boundary between server-side functions and private data sources? Why might this boundary require strong access control?
- Hint: Consider sensitive data storage and retrieval, and the need for strict authentication.
Task-2: Answer
Click to view a possible answer
These to be considered when building applications around LLMs
-
Trust Boundary 1 (TB-1):
- TB-1 lies between external endpoints (e.g., user input sources) and the LLM itself. Unlike traditional applications, where untrusted input may pose injection risks, LLMs require both their input and output to be treated as untrusted. This boundary is two-way, meaning that while users can manipulate input, they may also influence the LLM’s output in ways that could harm others.
- Example Scenario: An attacker could potentially use input to influence the LLM’s response, which may then deliver malicious content, such as a cross-site scripting (XSS) payload, to another user. Example: ChatGPT Cross-Site Scripting.
-
Trust Boundaries 2 (TB-2) and 3 (TB-3):
- Positioned between the LLM and server-side functions. Effective controls at this boundary prevent unfiltered GenAI output from directly interacting with backend functions (e.g., preventing direct execution of commands like
exec()), mitigating risks such as unintended code execution or XSS. - TB-3: Located between the LLM and private data sources, this boundary safeguards sensitive data from unauthorised access. Since LLMs lack built-in authorisation controls, strong access control measures at TB-3 are essential to prevent both users and the LLM itself from retrieving sensitive data without permission.
- Positioned between the LLM and server-side functions. Effective controls at this boundary prevent unfiltered GenAI output from directly interacting with backend functions (e.g., preventing direct execution of commands like
These trust boundaries are essential considerations when securing applications that involve GenAI technologies.
Assumptions
In this exercise, we will make several assumptions to help narrow our focus and provide a structured approach to threat modeling. Making assumptions is a standard practice in threat modeling exercises, as it allows us to focus on specific threat scenarios and vulnerabilities.
Please take 10 mins and think if you can come up with few of them
Click to view a possible answer
Here are the assumptions we will operate under for this hypothetical GenAI application:
-
Private or Fine-Tuned Model:
This application uses a private or custom fine-tuned GenAI model, similar to what is commonly seen in specialised or enterprise applications. -
OWASP Top 10 Compliance:
The application complies with standard OWASP Top 10 security guidelines. This means we will assume that basic web application security flaws (e.g., SQL injection, cross-site scripting) are already mitigated and are not the focus of this exercise. -
Authentication and Authorisation:
Proper authentication and authorisation controls are enforced for accessing the GenAI model itself. However, we assume that there are no access restrictions between the GenAI model and other internal components. -
Unfettered API Access:
Full access to the GenAI model’s API presents a potential risk, as seen in real-world applications. We assume that unrestricted API access to the model is a possible threat vector. -
DoS/DDoS Attacks Out of Scope:
Denial of Service (DoS) and Distributed Denial of Service (DDoS) attacks are beyond the scope of this threat model and will not be considered here. -
Conversation Storage for Debugging:
We assume that user conversations are stored to help debug and improve the GenAI model over time. This assumption introduces privacy considerations, which we will factor into the threat model. -
No Content Filters Between Model and Data Sources:
There are no content filters in place between the GenAI model and any backend functions or data sources. This is often seen in GenAI applications and increases the risk of sensitive information exposure. -
Server-Side Prompts Are Internal Only:
Prompts from server-side functions come exclusively from internal channels. Any external input (e.g., web lookups or email parsing) is performed by external source entities before reaching the GenAI application.
Task-3:
Review and Reflect:
Review each assumption and consider how it might affect the security and functionality of the GenAI application. Why do you think each assumption was included? Write a brief reflection on how these assumptions could influence the potential vulnerabilities we will examine.
Discussion:
How would these assumptions change if we were working with a public GenAI model instead of a private one? Discuss with the person next to you, how different assumptions might affect threat modeling considerations.
Threat Enumeration: STRIDE
Now that we have our DFD and assumptions in place, it’s time to begin threat enumeration. This is one of the most detailed parts of threat modeling, where we list potential threats based on our DFD and assumptions. Keep in mind that this exercise will not cover every possible threat but will focus on key vulnerabilities for our GenAI application.
In this lab, we’ll use the STRIDE framework, a common threat modeling tool that helps systematically identify threats across six categories. Each letter in STRIDE represents a specific type of threat. Understanding each category will guide you in spotting weaknesses and areas for improvement in the system.
STRIDE Categories
-
Spoofing (Authentication)
Spoofing involves impersonation. In our context, this could mean an attacker tries to gain unauthorised access by using someone else's credentials. -
Tampering (Integrity)
Tampering involves malicious changes to data. For instance, an attacker might modify data stored by the GenAI app or intercept and alter data as it flows between components. -
Repudiation (Non-repudiation)
Repudiation refers to actions that cannot be tracked back to the user. A lack of audit trails could allow users to deny performing certain actions, which can lead to accountability issues. -
Information Disclosure (Confidentiality)
Information disclosure involves unauthorised access to data. For example, users might access sensitive data from internal sources if boundaries aren’t properly secured. -
Denial of Service (Availability)
Denial of Service (DoS) aims to disrupt the application, preventing legitimate users from accessing it. Although DoS is out of scope here, it’s useful to consider briefly as it impacts availability. -
Elevation of Privilege (Authorisation)
Elevation of privilege refers to an attacker gaining unauthorised access to higher permissions within the application. This could happen if the GenAI app’s internal components lack strict access controls.
Task Overview
For each trust boundary (TB-1, TB-2, TB-3), we will examine the strengths (security measures or controls that reduce risk) and weaknesses (potential vulnerabilities or gaps) within each of the STRIDE categories.
Define Strengths and Weaknesses Tables:
-
For each trust boundary, you will create a table to document the strengths and weaknesses across each STRIDE category. This helps break down specific threats and understand where the system is robust versus where it may be vulnerable.
-
Example layout: (You can use this template)
STRIDE Category Strengths Weaknesses Spoofing Strong user authentication controls Lack of authentication between internal components Tampering Output filters prevent malicious changes No integrity check for data in transit Repudiation Logging mechanisms track user actions No traceability on certain LLM outputs Information Disclosure Access controls on sensitive data Weak encryption on data at rest Denial of Service Rate limiting to prevent abuse No controls for handling resource-intensive tasks Elevation of Privilege Privilege checks on data access Lack of strict role-based permissions
Trust Boundary-1 (TB-1): Users and External Entities Interacting with the GenAI App
Please use the template
This trust boundary (TB-1) exists between users or external entities (e.g., websites, emails) and the GenAI app. In this setup, TB-1 functions as a two-way trust boundary. This means we must evaluate weaknesses in controls not only for data coming into the GenAI app from external sources but also for data flowing out of the GenAI app back to users.
Since the GenAI app’s outputs can be influenced by external inputs, it’s essential to consider potential vulnerabilities that could affect users on both sides of this trust boundary.
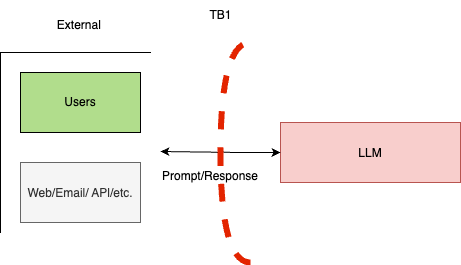
TB-1 Task: Identify Strengths and Weaknesses and list of vulnerabilities for TB-1:
Steps for Completing the Table
-
Identify Strengths
- Look for any assumptions or existing security measures that could serve as strengths for each component. For example:
- Spoofing: Does the system have controls like authentication to verify identities?
- Repudiation and Elevation of Privilege: The assumption of proper authentication and authorisation serves as a strength.
- Look for any assumptions or existing security measures that could serve as strengths for each component. For example:
-
Identify Weaknesses
- Focus on potential gaps or vulnerabilities not fully addressed. The table already notes some specific vulnerabilities (e.g., prompt injection, parameter modification). For each category, think about any other potential weaknesses that could affect system security.
- Tampering: Are there controls to prevent unauthorised changes to LLM parameters?
- Information Disclosure: Could the LLM accidentally reveal sensitive information?
- Focus on potential gaps or vulnerabilities not fully addressed. The table already notes some specific vulnerabilities (e.g., prompt injection, parameter modification). For each category, think about any other potential weaknesses that could affect system security.
-
Rely on the Weaknesses to produce a list of vulnerabilities, see the template.
Task-TB1: Answer
Click to view a possible answer
For the External points
| Category | Strengths, e.g. | Weaknesses, e.e.g. |
|---|---|---|
| 1-Spoofing | V1: Modify System prompt (prompt injection) | |
| 2-Tampering | V2: Modify LLM parameters (Temperature (randomness), length, model, etc.) | |
| 3-Repudiation | Proper authentication and authorisation (assumed) | |
| 4-Information Disclosure | V3: Input sensitive information to a third-party site (user behavior) | |
| 5-Denial of Service | ||
| 6-Elevation of Privilege | Proper authentication and authorisation (assumed) |
For LLMs
| Category | Strengths | Weaknesses |
|---|---|---|
| 1-Spoofing | - | - |
| 2-Tampering | - | - |
| 3-Repudiation | - | - |
| 4-Information Disclosure | - | V4: LLMs are unable to filter sensitive information (open research) |
| 5-Denial of Service | - | - |
| 6-Elevation of Privilege | - | - |
List of vulnerabilities
| V_ID | Description | E.g., |
|---|---|---|
| V1 | Modify System prompt (prompt injection) | Users can modify the system-level prompt restrictions to "jailbreak" the LLM and overwrite previous controls in place |
| V2 | Modify LLM parameters (temperature, length, model, etc.) | Users can modify API parameters as input to the LLM such as temperature, number of tokens returned, and model being used. |
| V3 | Input sensitive information to a third-party site (user behavior) | Users may knowingly or unknowingly submit private information such as HIPAA details or trade secrets into LLMs. |
| V4 | LLMs are unable to filter sensitive information (open research area) | LLMs are not able to hide sensitive information. Anything presented to an LLM can be retrieved by a user. This is an open area of research. |
Trust Boundary-2 (TB-2): LLM Interactions with Backend Functions
TB-2 Task: Identify Strengths and Weaknesses and list of vulnerabilities for TB-2:
-
TB-2 lies between the GenAI app (LLM) and backend functions or services. This boundary is essential for ensuring that the LLM’s requests to backend functions are properly filtered and controlled. In this context, we want to avoid passing unfiltered or unverified requests from the LLM to backend functions, as this could result in unintended actions or vulnerabilities.
-
Just as we apply both client-side and server-side controls in web applications, it’s critical to implement similar controls for LLM interactions with backend functions in GenAI applications.
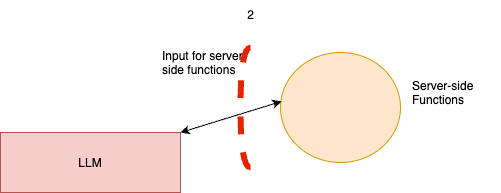
Task-TB2
To complete the strengths and weaknesses analysis for TB-2, consider the following:
Evaluate Controls on Data Passing Through TB-2 and the list of vulnerabilities
- Strengths: Identify existing controls that prevent unfiltered requests from reaching backend functions.
- Weaknesses: Look for areas where filtering, validation, or monitoring may be lacking between the LLM and backend functions.
Answers
Click to view a possible answer
LLMs
| Category | Strengths | Weaknesses |
|---|---|---|
| 1-Spoofing | - | V5: Output controlled by prompt input (unfiltered) |
| 2-Tampering | - | Output controlled by prompt input (unfiltered) |
| 3-Repudiation | - | - |
| 4-Information Disclosure | - | - |
| 5-Denial of Service | - | - |
| 6-Elevation of Privilege | - | - |
For Server-Side Functions
| Category | Strengths | Weaknesses |
|---|---|---|
| 1-Spoofing | Server-side functions maintain separate access to LLM from users | - |
| 2-Tampering | - | V6: Server-side output can be fed directly back into LLM (requires filter) |
| 3-Repudiation | - | - |
| 4-Information Disclosure | - | V6: Server-side output can be fed directly back into LLM (requires filter) |
| 5-Denial of Service | - | - |
| 6-Elevation of Privilege | - | - |
List of vulnerabilities
| V_ID | Description | E.g., |
|---|---|---|
| V5 | Output controlled by prompt input (unfiltered) | LLM output can be controlled by users and external entities. Unfiltered acceptance of LLM output could lead to unintended code execution. |
| V6 | Server-side output can be fed directly back into LLM (requires filter) | Unrestricted input to server-side functions can result in sensitive information disclosure or server-side request forgery (SSRF). Server-side controls would mitigate this impact. |
Trust Boundary 3 (TB-3): LLM Interactions with Private Data Stores
TB-3 represents the boundary between the GenAI app (LLM) and private data stores, which may include reference documentation, internal websites, or private databases.
The primary goal at TB-3 is to enforce strong authorisation controls and apply the principle of least privilege, ensuring the LLM only accesses necessary information. Since LLMs lack built-in authorisation capabilities, these controls must be managed externally.
Task-TB3
To complete the strengths and weaknesses analysis for TB-3, focus on potential vulnerabilities and existing controls that could impact the security of private data stores accessed by the LLM. Use the following to guide your analysis for each STRIDE category.
- Assess Authorisation Controls for Private Data Access
- Strengths: Identify any current measures that limit or control the LLM’s access to private data stores.
- Weaknesses: Look for gaps in authorisation or access control that could allow unauthorised access or data leakage.
Answers TB-3
Click to view a possible answer
For the LLMs
| Category | Strengths | Weaknesses |
|---|---|---|
| 1-Spoofing | - | V5: Output controlled by prompt |
| input (unfiltered) | ||
| 2-Tampering | - | V5: Output controlled by prompt |
| input (unfiltered) | ||
| 3-Repudiation | - | - |
| 4-Information Disclosure | - | - |
| 5-Denial of Service | - | - |
| 6-Elevation of Privilege | - | - |
Private Data Sources
| Category | Strengths | Weaknesses |
|---|---|---|
| 1-Spoofing | - | - |
| 2-Tampering | - | - |
| 3-Repudiation | - | - |
| 4-Information Disclosure | - | V7: Access to sensitive information |
| 5-Denial of Service | - | - |
| 6-Elevation of Privilege | - | - |
List of vulnerabilities
| V_ID | Description | E.g., |
|---|---|---|
| V5 | Output controlled by prompt input (unfiltered) | LLM output can be controlled by users and external entities. Unfiltered acceptance of LLM output could lead to unintended code execution. |
| V7 | Access to sensitive information | LLMs have no concept of authorisation or confidentiality. Unrestricted access to private data stores would allow users to retrieve sensitive information. |
Other Issues:
1. Can we consider hallucinations as a vulnerability?
Use the following to discuss
2. What about training data poisoning, bias, or hate speech?
Recommendations for Mitigation
Based on the analysis of each trust boundary (TB-1, TB-2, TB-3), here are key recommendations to mitigate vulnerabilities and enhance the security of the GenAI application. Each recommendation is designed to address specific weaknesses/vuln and reinforce best practices for handling GenAI interactions with external inputs, backend functions, and private data. Use the table (section 3 in the template) in the template to define a mitigation plan/stratigy for each vulnerabilities. Like so:
| REC_ID | Recommendations for Mitigation |
|---|---|
| REC1 | Avoid training GenAI models on non-public or sensitive data. Treat all GenAI output as untrusted and apply restrictions based on the data or actions the model requests. |
| REC2 | |
| REC3 | |
| REC4 | |
| REC5 | |
| REC6 | |
| REC7 |
Click to view a possible answer of mitigations
| REC_ID | Recommendations for Mitigation |
|---|---|
| REC1 | Avoid training GenAI models on non-public or sensitive data. Treat all GenAI output as untrusted and apply restrictions based on the data or actions the model requests. |
| REC2 | Limit API exposure to external prompts. Treat all external inputs as untrusted and apply filtering where necessary to prevent injection or manipulation. |
| REC3 | Educate users on safe usage practices during signup, and provide regular notifications reminding them of security guidelines when interacting with the GenAI app. |
| REC4 | Do not train GenAI models on sensitive data. Instead, apply authorisation controls directly at the data source, as the GenAI app lacks inherent authorisation. |
| REC5 | Treat all GenAI output as untrusted, enforcing strict validation before using it in other functions to reduce the impact of potential prompt manipulation. |
| REC6 | Apply filtering to server-side function outputs, and sanitise any sensitive data before using the output for retraining or sharing it with users. |
| REC7 | Treat GenAI access to data like typical user access, enforcing authentication and authorisation controls for all data interactions, as the model itself cannot do this. |
More: Microsoft Threat Modeling Tool (useful tool)
The Microsoft Threat Modeling Tool is a practical, free tool designed to help users identify security threats in a system's design. It allows you to create visual representations of systems and guides you in spotting potential vulnerabilities early on. However, I’m currently unable to use it on the university machines as it hasn’t yet been validated by IT services. You are welcome to try it on your personal devices. Also, feel free to use in your assignennmt for Part-3.
To get started, see this